

In this article, we're diving into the world of generative AI, focusing on a core concept called tokenization. Whether you're a curious learner, a tech enthusiast, or someone just trying to keep up with the rapid advancements in AI, this piece is for you.
We'll explore what tokenization is, why it's important, and how it impacts the functioning and costs of AI models like ChatGPT.
With my experience in breaking down complex tech topics, I'll ensure that you come away with a solid understanding of tokenization and its role in AI, without needing a degree in computer science.
In this article, we will:
How does tokenization break down a prompt
How a real prompt is broken down
Cost of a prompt
How Tokenization Breaks Down a Prompt
Tokenization, in the realm of Artificial Intelligence (AI), refers to the process of converting input text into smaller units or ‘tokens’ such as words or subwords. This is foundational for Natural Language Processing (NLP) tasks, enabling AI to analyze and understand human language. Iguazio
In other words, tokenization is like chopping a log into kindling: it breaks down text into smaller, bite-sized pieces that the AI can understand and work with.
Breaking Down Text into Tokens
Basic Units
In tokenization, the text is broken down into smaller pieces. These pieces can be words, parts of words, or even individual characters, depending on the tokenization approach.
Subword Tokenization
Many modern LLMs use subword tokenization, where common words might be kept as whole tokens, but less common words are broken down into smaller, more frequently occurring pieces.
This approach balances the vocabulary size and the ability to handle rare or unknown words.
Vocabulary Mapping
Pre-defined Vocabulary
LLMs have a pre-defined vocabulary list. Each unique token in this list is assigned a specific numeric ID.
Out-of-Vocabulary Words
Words or phrases not in the vocabulary are handled using special tokens or by breaking them down into smaller tokens that are in the vocabulary.
Encoding and Embedding
Encoding
Once the text is tokenized, the tokens are converted into their corresponding numeric IDs based on the model's vocabulary.
Embeddings
These numeric IDs are then transformed into embeddings, which are high-dimensional vectors.
Embeddings capture semantic and syntactic information about the tokens, allowing the model to understand the context and relationships between words.
Contextual Understanding
Input to Model
The embeddings are fed into the neural network layers of the LLM. The model processes these embeddings to understand the context and meaning of the text.
Attention Mechanisms
Techniques like attention mechanisms (especially in models like transformers) help the model focus on relevant parts of the input for a given task, further enhancing understanding and generating appropriate responses.
Handling Special Tokens
Special Purpose Tokens
LLMs often use special tokens for specific purposes, like marking the beginning and end of a sentence, padding, and handling unknown words.
Role in Processing
These tokens play a role in helping the model understand the structure of the input text and manage varying lengths of input sequences.
Real World Prompt
Now let's take a real-world prompt and walk through the tokenization process step by step.

Initial Text Input
The prompt "If a burrito ate a human, what would it taste like?" is our starting point.
This is the raw text that we want the language model to process.
Breaking Down into Tokens
In this step, the sentence is split into smaller units. Depending on the tokenization method, these could be words, subwords, or characters. For simplicity, let's assume a basic word-level tokenization.
If the model uses subword tokenization, more common words might remain as they are, while less common words might be broken down further. For example in the prompt below “burrito” is split into two subwords as “bur” - “rito”.
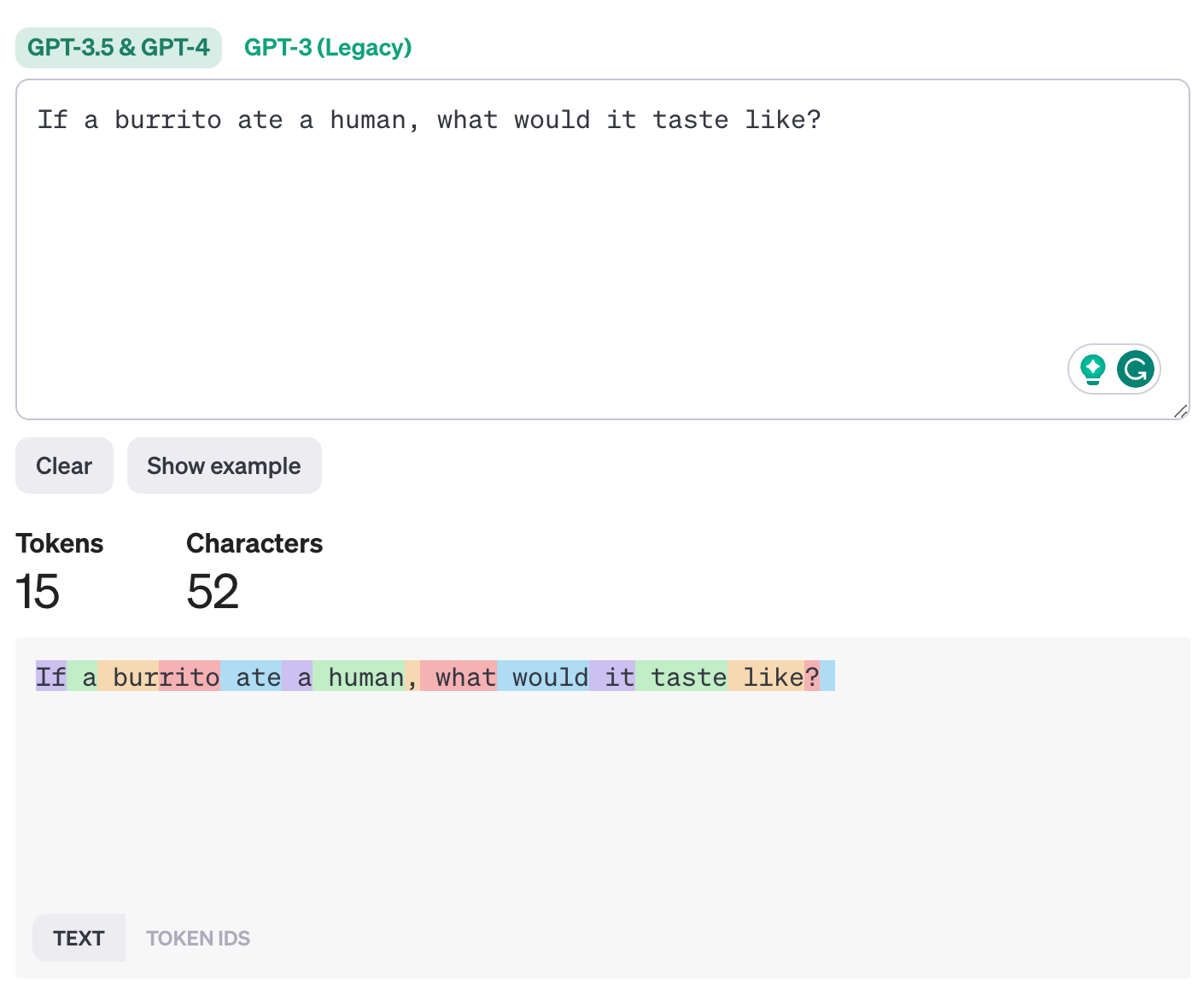
Mapping to Vocabulary IDs
Each token is then mapped to a unique ID based on the model's vocabulary. For instance, if the vocabulary has the word "If" as ID 2746, "a" as ID 264, and so on, the tokens are converted to these IDs.
Our sentence becomes a series of numbers, each representing a word or subword.
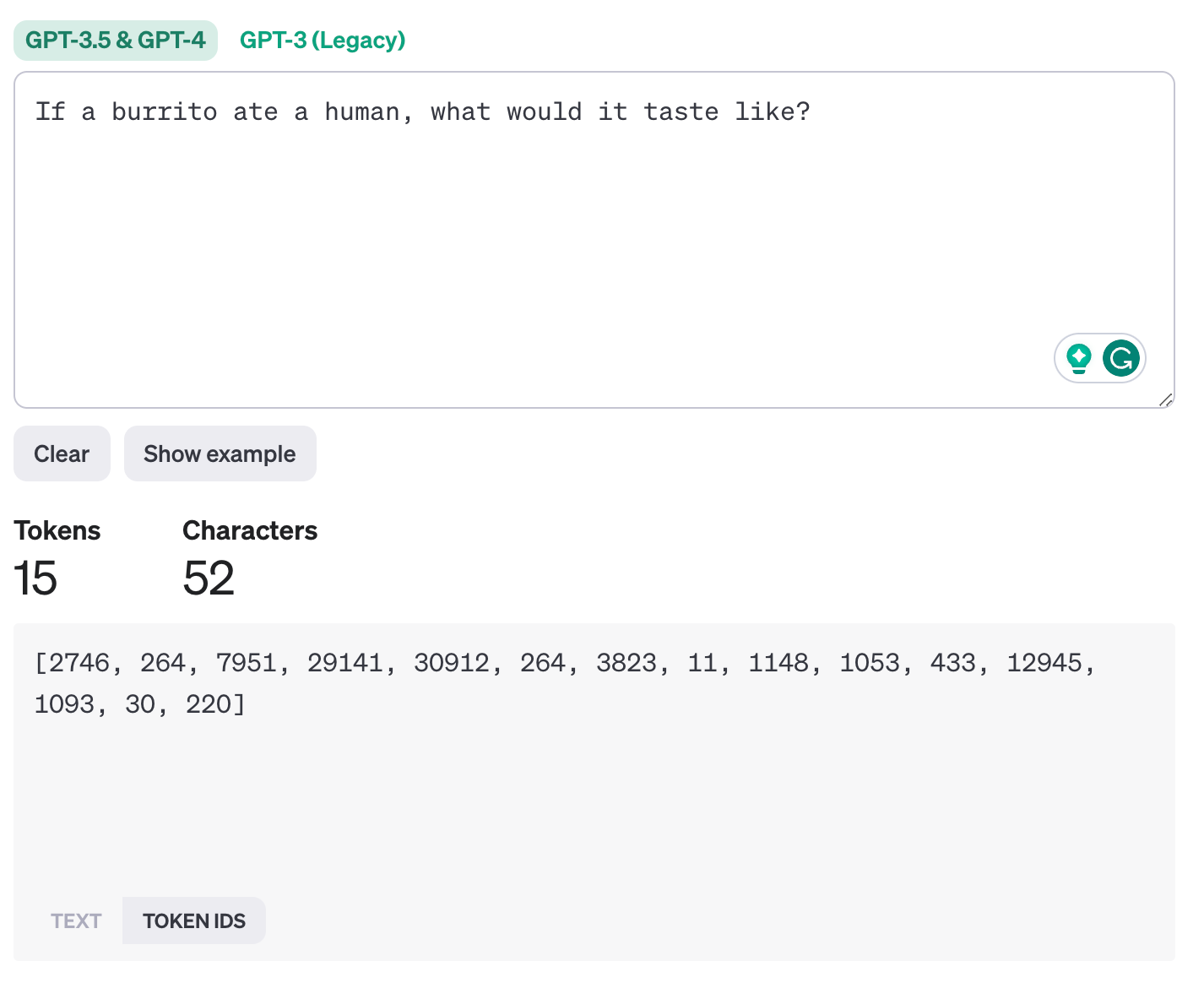
Handling Out-of-Vocabulary Words
If a word in the sentence doesn't exist in the model's vocabulary (say "fox" is not in the vocabulary), it is handled using special techniques.
It might be replaced with a special token like [UNK] (unknown) or broken down into known subwords or characters.
Adding Special Tokens
Depending on the model, special tokens might be added. For example, tokens indicating the start and end of a sentence, like [START] and [END], or [CLS] and [SEP] in some models.
This helps the model understand sentence boundaries. In the example above this is highlighted by the blue box (ID 220) at the end of the sentence where I used a space.
Encoding and Embeddings
The numeric IDs are then converted into embeddings. These are high-dimensional vectors that represent each token in a way that captures semantic and syntactic information, allowing the model to process the text meaningfully.
Feeding into the Language Model
Finally, these embeddings are fed into the language model. The model, through its layers and mechanisms (like attention in transformer models), processes these embeddings, understanding the context and relationships to generate a response or perform the desired task.
The cost of a prompt
So how much does it cost to get a result from a prompt? A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words)
Cost
According to OpenAI’s pricing below

If I take my input…
Input

And ChatGPT’s sassy output…
Output

This would result in a total cost of $4.59
Conclusion
The world of generative AI is fascinating and complex, but understanding its core concepts like tokenization doesn't have to be daunting. By grasping the basics of how AI models process language, you'll be better equipped to appreciate the intricacies of AI communication and the factors that influence its efficiency and costs.
Remember, the journey into AI literacy is ongoing, and understanding tokenization is a significant step in demystifying this revolutionary technology. Stay curious, and don't hesitate to explore further!
Sources
"In their comprehensive study on tokenizer choice in LLM training, [Author(s)], in their paper 'Tokenizer Choice For LLM Training: Negligible or Crucial?' (arXiv:2310.08754)..."
"The challenges of representing and tokenizing temporal data in LLMs are examined in 'The first step is the hardest: Pitfalls of Representing and Tokenizing Temporal Data for Large Language Models' (arXiv:2309.06236) by [Author(s)]..."
"As discussed in the Luminis blog 'LLM Series, part 1: A Comprehensive Introduction to Large Language Models,' tokenization plays a crucial role..."
"For an insightful perspective on Byte-Pair Encoding and its implementation in tokenization, refer to the article on Towards Data Science titled 'Byte Pair Encoding: Subword-based Tokenization Algorithm'."
"Lukas Selin provides a detailed understanding of tokens in LLMs in his LinkedIn article 'Demystifying Tokens in LLMs: Understanding the Building Blocks'."